
تجزیه و تحلیل داده بزرگ
چالش استخراج از دادههای بزرگ به طرق مختلف، مشابه یک مشکل هوش تجاری از دادههای تجاری است.
در طول چند سال گذشته، سازمانها در بخشهای دولتی و خصوصی تصمیمات استراتژیکی برای تبدیل دادههای بزرگ به مزیت رقابتی ایجاد کردهاند. چالش استخراج از دادههای بزرگ به طرق مختلف، مشابه یک مشکل هوش تجاری از دادههای تجاری است.
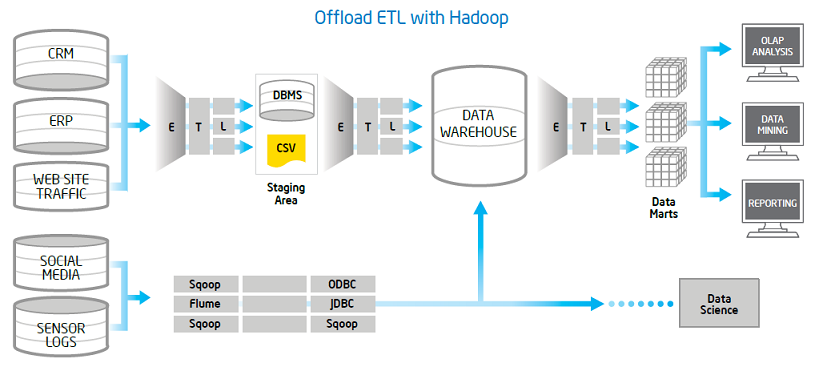
در قلب این چالش، فرایندیست که دادهها را از منابع مختلف استخراج مینماید، آنها را به نیازهای تحلیلی شما تبدیل نموده و در یک انبار داده برای تجزیه و تحلیل بعدی بارگذاری می نماید. اصطلاحا به این کار فرآیند “استخراج، تبدیل و بارگذاری” یا به اختصار (ETL) می گویند.
ماهیت داده های بزرگ نیازمند زیرساخت های فرآیند مقرون به صرفه میباشد. Apache Hadoop یک استاندارد واقعی برای مدیریت دادههای بزرگ میباشد. این مقاله به بررسی برخی از ملاحظات سخت افزاری و نرم افزاری در استفاده از Hadoop برای ETL می پردازد.
اتصال EDW و داده بزرگ
Apache Hadoop
Apache Hadoop یک پلت فرم نرم افزاری رایگان برای ذخیره و پردازش دادهها است.
به زبان جاوا نوشته شده و برروی یکی از کلاسترهای سرورهای استاندارد قرار گرفته است. با استفاده از Hadoop، میتوان با اطمینان، دادههای حجیم را بر روی دهها هزار سرور ذخیره کرد و در هزینه های خود صرفه جویی نمود.
Map Reduce
زبانهای برنامه نویسیای هستند که توسعه را با استفاده از چارچوب MapReduce ساده می کنند.
HiveQL دارای گواهی SQL است و از زیر مجموعه ی نحوی پشتیبانی میکند. با وجود اینکه آهسته است، Hive به طور فعال به کمک Apache HBase و HDFS فعال میشود. یک زبان رویهای است که انتصابهای سطح بالا را برای MapReduce فراهم میکند. شما میتوانید آن را با استفاده از توابع تعریف شده در جاوا، پایتون و دیگر زبان ها گسترش دهید.
Apache Hive
Apache Hive یکی از زبانهای برنامهنویسی است که توسعه برنامههای کاربردی را با استفاده از چارچوب MapReduce آسان میکند.
با وجود اینکه آهسته است، Hive به طور فعال توسط جامعه توسعه دهنده برای فعال کردن نمایش داده شده با زمان پایین در Apache HBase و HDFS فعال میشود. Pig Latin یک زبان برنامهنویسی رویه است که انتصابهای سطح بالا را برای MapReduce فراهم میکند.
شما میتوانید آن را با استفاده از توابع تعریف شده توسط کاربر نوشته شده در جاوا، پایتون و دیگر زبانها گسترش دهید.
Apache Flume
Apache Flume یک سیستم توزیع شده برای جمعآوری و انتقال دادههای بزرگ از منابع مختلف به HDFS یا یکی دیگر از فروشگاههای داده مرکزی است.
سازمانها معمولا فایلهای log را در سرورهای برنامه یا سایر سیستمها جمعآوری میکنند و فایلهای log را آرشیو میکنند تا مطابق با مقررات باشند.
فلوم قادر به گرفتن و تجزیه و تحلیل اطلاعات غیر ساختار یافته یا نیمه ساختاریافته در Hadoop است که میتواند ارزش آفرینی کند.
راهکارهای سفارشی
بررسی نیازهای اطلاعات
به خوبی شناخته شده است که حجم، سرعت و انواع داده ها با سرعت نمایش داده می شود.
سازمان هایی که یاد می گیرند چگونه داده ها را به سمت کسب و کار خود هدایت و ادغام کنند تا مزیت رقابتی کسب کنند.
می دانید که چگونه داده های بزرگ می توانند برای شما ارزش ایجاد کنند اطمینان حاصل کنید که می توانید اطلاعات بزرگ را جمع آوری و تجزیه و تحلیل کنید استفاده از بینش هایی که داده های بزرگ فراهم می کند استفاده کنید.
خدمات
مشاوره
- تعریف و اعتبارسنجی مورد کسب و کار و استفاده از آن
- معماری و طراحی راه حل
- تعریف مدل عامل و استقرار
پیاده سازی
- معماری مرجع فنی
- پایان دادن به پایان راه حل توسعه از ساخت از طریق پشتیبانی
- ادغام با سیستم های معامله
سکو
- ارزیابی و انتخاب
- اندازه، نصب و پیکربندی
- تعمیر و نگهداری و پشتیبانی
مدیریت جمعیت
در حوادث مهم، مهم است که خطرهای امنیتی را تا آنجا که ممکن است کاهش دهیم، زیرا ما فقط بدانیم که گاهی اوقات اشتباه می کنیم. فهم مردم / بازدیدکنندگان و سازماندهندگان برای مدیریت جمعیت ضروری است.با تجسم این اطلاعات و به اشتراکگذاری آن با خدمات اضطراری، یک سازمان میتواند به سرعت به آنچه که در یک رویداد اتفاق میافتد پاسخ دهد.
Data Lake
Data Lake اطلاعات را در منابع داده های ساختاری و فضایی ناهمگن ذخیره می کند با حالت های ذخیره سازی پیچیده که به طور قابل اعتماد در هر زمانی قابل دسترسی هستند تا به پشتیبانی از تصمیمات کسب و کار شما بهینه کمک کنند. یک Data Lake عملا مترادف با یک انبار داده مدرن است. همانطور که کاربران نهایی با چالش های بزرگتر و پیچیده تر با نوآوری های جدید و پیشرفت تکنولوژی مواجه می شوند، که به نوبه خود خواسته های جدید در سیستم های ذخیره سازی داده ها را تحمیل می کند، تکامل پردازش داده ها و ذخیره سازی، گام بعدی اجتناب ناپذیر در حفظ چنین پیشرفت هایی است . این تغییر پارادایم منجر به یک رویکرد جدید و مفهومی متفاوت برای ذخیره سازی داده ها شده است – ذخیره سازی انواع داده ها در یک مکان بدون توجه به اندازه و پیچیدگی، با استفاده از افزایش توان محاسباتی با موازی سازی گسترده و پردازش توزیع شده و توانایی پردازش داده های بزرگ در یک زمان معین و با حداقل بار در سیستم های فعلی.
در حالی که مدل انبار استاندارد داده ها به طور سنتی داده ها را در یک ساختار سلسله مراتبی ذخیره می کند، معماری Data Lake هر عنصر داده را یک شناسه ی منحصر به فرد است که شامل برچسب های ابرداده گسترده ای مرتبط با عنصر مربوطه است. هنگامی که مورد نیاز توسط روش های عملیاتی کسب و کار، تجزیه و تحلیل را می توان در هر زمان در گروه های داده مربوطه ذخیره شده در مرکز داده Lake Data که این داده ها را به اطلاعات کاربر بالقوه مفید و قابل استفاده تبدیل می کند، انجام می دهد.
مشاوران ما آماده هستند تا شما را با مهارت و تخصص فنی و حرفه ای خود برای موفقیت راه حل های Data Lake و ایجاد یک انبار داده مدرن آماده سازند، که به شما امکان می دهد اطلاعات را به اطلاعات ضروری بازیابی، پردازش و تبدیل کنید.ِ